Zadania 3 i 4
Inicjalizacja grupy w sieci single-hop
Algorytm 1 EstymacjaRozmiaru$(t_0, \alpha, k)$
Inicjalizacja:
$\xi \gets losowaLiczba([0,1])$
W chwili $t_0$ zgodnie z moim zegarem:
czekaj przez czas $x_i$
for $i=1,2,\ldots,k$
nadaj sygnał długości $a$
słuchaj kanał przez czas $1-a$
$S_i \gets$ całkowity czas ciszy w tej rundzie
$S \gets \min\{S_1,S_2,\ldots,S_k\}$
return $\hat{n} \gets \ln(S) / \ln(1-a)$
Poprawność opisanego algorytmu opiera się na poniższym twierdzeniu,
którego prawdziwość została dowiedziona.
Twierdzenie 1 Załóżmy, że Algorytm 1 jest uruchamiany z parametrem $k\geqslant 3$ oraz, że $\Delta t \leqslant k-2$ będzie największą różnicą we wskazaniach zegarów (po wszystkich parach stacji). Wówczas dla dowolnie wybranego urządzenia $D$ istnieje $i\in \{1,2,\ldots,k\}$ takie, że każde urządzenie nadaje w te $i$-tej rundzie urządzenia $D$ przez czas $a$ oraz zachodzi relacja $S_i = \min\{ S_1, S_2, \ldots, S_n \}$.
Zbadaliśmy również właściwości wykorzystywanego w algorytmie estymatora. Wyniki są zawarte w następujących twierdzeniach.Twierdzenie 2 Jeśli $a \leqslant 1/n$ to wartość oczekiwana estymatora $\hat{n} = \ln(S)/\ln(1-a)$ wyraża się wzorem \begin{equation*} E[\hat{n}] = (n-1) - \frac12 a(n-1)\frac{e^{an}-1}{an}+O\bigl(\frac1n\bigr) \end{equation*}
Twierdzenie 3 Jeśli $a \leqslant 1/n$ to wariancja estymatora $\hat{n} = \ln(S) / \ln(1-a)$ wyraża się wzorem \begin{equation*} Var[\hat{n}] = 2\sigma_3(an)an^2 + (1-3\sigma_1(an))an + 4\sigma_1^2(an) + 4\sigma_2(an) - 6\sigma_1(an) + o(an)~. \end{equation*} gdzie \begin{equation*} \sigma_1(x) = \frac{e^x-1}{x}, \quad \sigma_2(x) = \frac{e^x-1-x}{x^2}, \quad \sigma_3(x) = \frac{e^x-1-x-x^2/2}{x^3}~. \end{equation*}
Z Twierdzenia 3 można wydedukować, iż dla $a \leqslant 1/n$ mamy $Var[\hat{n}] = O(an^2)$. Rozpatrywany estymator jest zatem dobrze skoncentrowany (porównaj: Rys. 2).
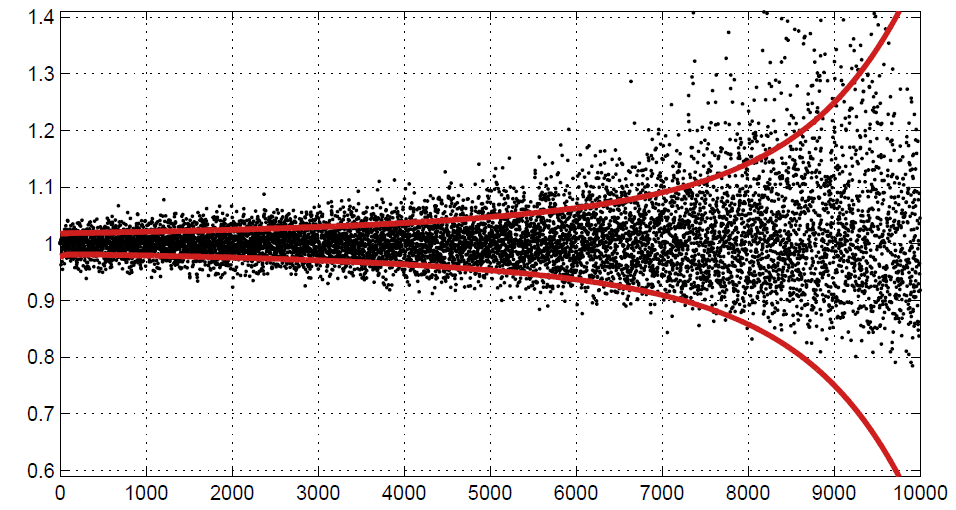
Wykres przedstawia wartości $\hat{n}/n$ (kropki) dla $n=1, \ldots, 10000$ oraz $a=1/1000$. Linie ciągłe przedstawiają wartości funkcji $1 \mp \sqrt{Var[\hat{n}]/n}$. Wykres sugeruje, że estymator jest silnie skoncentrowany również poza zakresem objętym formalną analizą
Implementacja
Rozważania teoretyczne oraz analiza wyników zadania drugiego pokazały, że jednym z najistotniejszych elementów podczas inicjalizacji grupy w sieci single-hop jest zliczenie węzłów należących do tej grupy. Wyzwaniem jest fakt, iż węzły nie mają idealnie zsynchronizowanych zegarów oraz na ich działanie wpływa również środowisko zewnętrzne zachowujące się w sposób nieprzewidywalny. W związku z tym najważniejsze kroki podczas realizacji zadania czwartego to:-
Implementacja algorytmu asynchronicznego zliczania, stworzonego
przez Politechnikę Wrocławską
Etap ten obejmował przede wszystkim takie skonfigurowanie
zaimplementowanych w zadaniu 13 elementów sieci, by po włączeniu się w
losowym momencie (efekt braku synchronizacji zegarów) włączyły się do
działania. Następnie węzły dokonują operacji zliczania transmitując
sygnał radiowy oraz nasłuchując transmisji od innych węzłów. Wyniki
pomiarów i analizy na węzłach zapisywane są w bazie danych.
- Konfiguracja stworzonej w zad. 13 sieci bezprzewodowej
umożliwiające zasymulowanie działania w rzeczywistych warunkach
interferencyjnych
Sieć zaimplementowana w zad. 13 posiada zamodelowane najważniejsze
zjawiska dotyczące sieci radiowych takie jak straty propagacyjne sygnału,
zaniki szybkie, zaniki wolne czy zakłócenia (interferencje). Dodatkowo
modelowane są parametry węzłów takie jak czułość odbiornika czy moc
nadajnika. Aby przybliżyć model sieci do rzeczywistych warunków
interferencyjnych zaproponowany został poniższy model rozmieszczenia
węzłów. Stacje nadawcze rozmieszczono w kwadracie o boku 100 metrów, co
ma odpowiadać np. hali w fabryce. Obszar ten jest zaznaczony jako „A” na
poniższym schemacie:
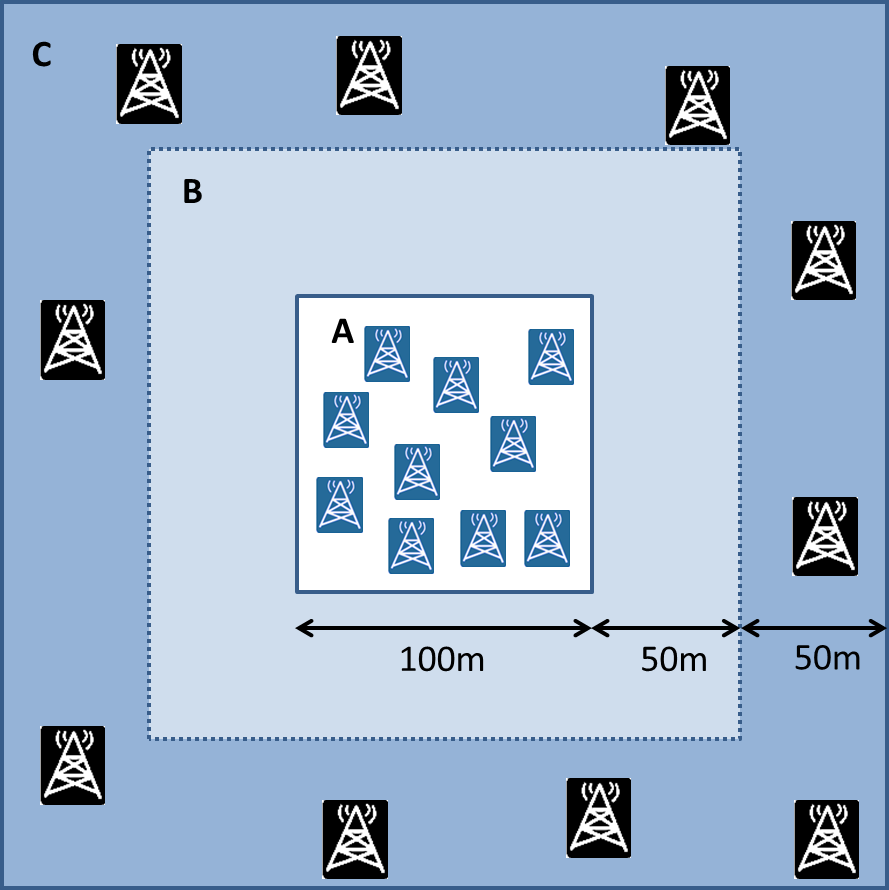
Schemat rozmieszczenia użytkowników z zaznaczonymi obszarami
- Analiza wyników symulacji, w szczególności sugestia dotycząca
parametrów konfiguracyjnych algorytmu w zależności od rodzaju środowiska
oraz parametrów konfiguracyjnych rzeczywistych urządzeń
Podstawowymi parametrami węzłów sprawdzanymi podczas kampanii
symulacyjnych były:
- Czułość odbiornika
- Długość jednej rundy algorytmu zliczania, a także powiązana z nią zakładana liczba stacji
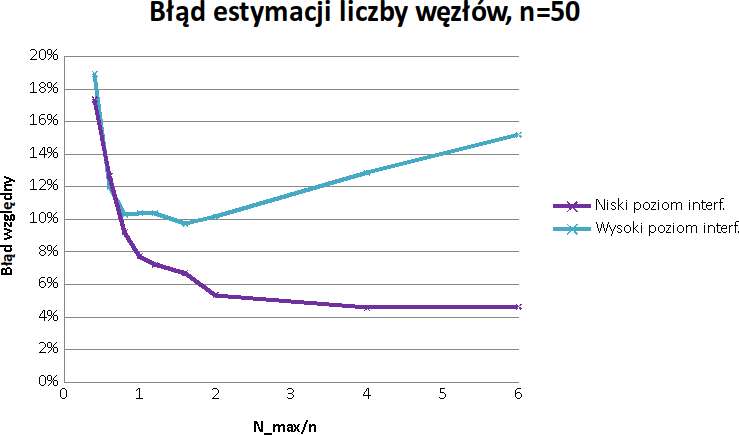
Wykres zależności średniego błędu względnego szacowania liczby węzłów w sieci w zależności od stosunku zakładanej liczby stacji ($N\_max$) do rzeczywistej liczby stacji ($n=50$), dla przypadku niskich i wysokich interferencji
- ocena przydatności algorytmu w realnych zastosowaniach
Symulacje sieci radiowej pokazują, że algorytm dobrze spełnia stawiane
przed nim wymagania, w szczególności:
- Błąd względny zliczania utrzymuje się na akceptowalnym poziomie dla dużego zakresu przeszacowania maksymalnej liczby węzłów oraz dużego poziomu interferencji zewnętrznych
- Algorytm umożliwia działanie węzłów przed ich dokładnym zsynchronizowaniem, co jest bardzo istotną cechą na etapie inicjalizacji sieci
- Algorytm działa w oparciu o wykrywanie fali nośnej, a takie rozwiązania, z racji prostoty i braku konieczności dekodowania informacji, zazwyczaj są bardziej energooszczędne od skomplikowanych algorytmów